Pada artikel ini, kita akan membahas cara mengalokasikan BERBEDA memori melalui “ pytorch_cuda_alloc_conf ' metode.
Apa itu Metode “pytorch_cuda_alloc_conf” di PyTorch?
Pada dasarnya, “ pytorch_cuda_alloc_conf ” adalah variabel lingkungan dalam kerangka PyTorch. Variabel ini memungkinkan pengelolaan sumber daya pemrosesan yang tersedia secara efisien yang berarti model berjalan dan memberikan hasil dalam waktu sesingkat mungkin. Jika tidak dilakukan dengan benar, “ BERBEDA ” platform komputasi akan menampilkan “ kehabisan memori ” kesalahan dan memengaruhi waktu proses. Model yang akan dilatih pada data bervolume besar atau memiliki “ ukuran kumpulan ” dapat menghasilkan kesalahan runtime karena pengaturan default mungkin tidak cukup untuk kesalahan tersebut.
“ pytorch_cuda_alloc_conf ” variabel menggunakan yang berikut “ pilihan ” untuk menangani alokasi sumber daya:
- warga asli : Opsi ini menggunakan pengaturan yang sudah tersedia di PyTorch untuk mengalokasikan memori ke model yang sedang berlangsung.
- max_split_size_mb : Ini memastikan bahwa blok kode apa pun yang lebih besar dari ukuran yang ditentukan tidak terpecah. Ini adalah alat yang ampuh untuk mencegah “ fragmentasi ”. Kami akan menggunakan opsi ini untuk demonstrasi di artikel ini.
- roundup_power2_divisions : Opsi ini membulatkan ukuran alokasi ke “” terdekat kekuatan 2 ” pembagian dalam megabyte (MB).
- roundup_bypass_threshold_mb: Ini dapat mengumpulkan ukuran alokasi untuk daftar permintaan apa pun yang melebihi ambang batas yang ditentukan.
- ambang batas_koleksi_sampah : Ini mencegah latensi dengan memanfaatkan memori yang tersedia dari GPU secara real time untuk memastikan bahwa protokol reclaim-all tidak dimulai.
Bagaimana Mengalokasikan Memori Menggunakan Metode “pytorch_cuda_alloc_conf”?
Model apa pun dengan kumpulan data yang cukup besar memerlukan alokasi memori tambahan yang lebih besar daripada yang ditetapkan secara default. Alokasi khusus perlu ditentukan dengan mempertimbangkan persyaratan model dan sumber daya perangkat keras yang tersedia.
Ikuti langkah-langkah yang diberikan di bawah ini untuk menggunakan “ pytorch_cuda_alloc_conf ” metode di Google Colab IDE untuk mengalokasikan lebih banyak memori ke model pembelajaran mesin yang kompleks:
Langkah 1: Buka Google Colab
Telusuri Google Kolaboratif di browser dan buat ' Buku Catatan Baru ” untuk mulai bekerja:
Langkah 2: Siapkan Model PyTorch Kustom
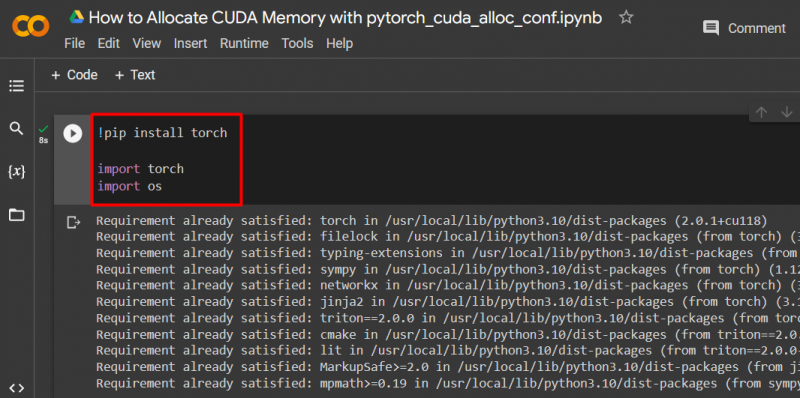
Siapkan model PyTorch dengan menggunakan “ !pip ” paket instalasi untuk menginstal “ obor ” perpustakaan dan “ impor ” perintah untuk mengimpor “ obor ' Dan ' Anda ” perpustakaan ke dalam proyek:
impor obor
impor kami
Perpustakaan berikut diperlukan untuk proyek ini:
- Obor – Ini adalah perpustakaan dasar yang menjadi dasar PyTorch.
- ANDA – “ sistem operasi ” perpustakaan digunakan untuk menangani tugas-tugas yang berkaitan dengan variabel lingkungan seperti “ pytorch_cuda_alloc_conf ” serta direktori sistem dan izin file:
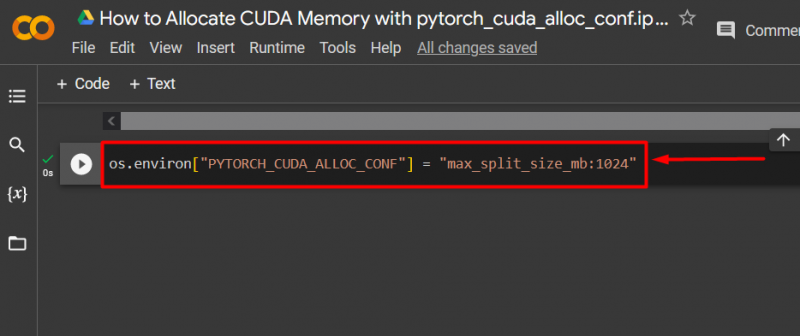
Langkah 3: Alokasikan Memori CUDA
Menggunakan ' pytorch_cuda_alloc_conf ” metode untuk menentukan ukuran pemisahan maksimum menggunakan “ max_split_size_mb ”:
Langkah 4: Lanjutkan dengan Proyek PyTorch Anda
Setelah menentukan “ BERBEDA ” alokasi ruang dengan “ max_split_size_mb ” opsi, lanjutkan mengerjakan proyek PyTorch seperti biasa tanpa takut akan “ kehabisan memori ” kesalahan.
Catatan : Anda dapat mengakses notebook Google Colab kami di sini tautan .
Tip Pro
Seperti disebutkan sebelumnya, “ pytorch_cuda_alloc_conf ” Metode dapat mengambil salah satu opsi yang disediakan di atas. Gunakan sesuai dengan kebutuhan spesifik proyek pembelajaran mendalam Anda.
Kesuksesan! Kami baru saja mendemonstrasikan cara menggunakan “ pytorch_cuda_alloc_conf ” metode untuk menentukan “ max_split_size_mb ” untuk proyek PyTorch.
Kesimpulan
Menggunakan ' pytorch_cuda_alloc_conf ” metode untuk mengalokasikan memori CUDA dengan menggunakan salah satu opsi yang tersedia sesuai kebutuhan model. Masing-masing opsi ini dimaksudkan untuk meringankan masalah pemrosesan tertentu dalam proyek PyTorch untuk runtime yang lebih baik dan pengoperasian yang lebih lancar. Pada artikel ini, kami telah memamerkan sintaks untuk menggunakan “ max_split_size_mb ” opsi untuk menentukan ukuran maksimum pemisahan.