Panduan ini akan mengilustrasikan proses penggunaan ringkasan percakapan di LangChain.
Bagaimana Cara Menggunakan Ringkasan Percakapan di LangChain?
LangChain menyediakan perpustakaan seperti ConversationSummaryMemory yang dapat mengekstrak ringkasan lengkap dari obrolan atau percakapan. Dapat digunakan untuk mendapatkan informasi utama percakapan tanpa harus membaca semua pesan dan teks yang tersedia dalam obrolan.
Untuk mempelajari proses penggunaan ringkasan percakapan di LangChain, cukup ikuti langkah-langkah berikut:
Langkah 1: Instal Modul
Pertama, instal kerangka LangChain untuk mendapatkan dependensi atau pustakanya menggunakan kode berikut:
pip instal langchain
Sekarang, instal modul OpenAI setelah menginstal LangChain menggunakan perintah pip:
pip instal openai 
Setelah menginstal modul, cukup mengatur lingkungan menggunakan kode berikut setelah mendapatkan kunci API dari akun OpenAI:
impor Andaimpor dapatkan pass
Anda . sekitar [ 'OPENAI_API_KEY' ] = dapatkan pass . dapatkan pass ( 'Kunci API OpenAI:' )
Langkah 2: Menggunakan Ringkasan Percakapan
Ikuti proses penggunaan ringkasan percakapan dengan mengimpor perpustakaan dari LangChain:
dari rantailang. Penyimpanan impor Memori Ringkasan Percakapan , Riwayat Pesan Obrolandari rantailang. llms impor OpenAI
Konfigurasikan memori model menggunakan metode ConversationSummaryMemory() dan OpenAI() dan simpan data di dalamnya:
Penyimpanan = Memori Ringkasan Percakapan ( llm = OpenAI ( suhu = 0 ) )Penyimpanan. simpan_konteks ( { 'memasukkan' : 'Halo' } , { 'keluaran' : 'Hai' } )
Jalankan memori dengan memanggil memuat_memori_variabel() metode untuk mengekstrak data dari memori:
Penyimpanan. memuat_memori_variabel ( { } ) 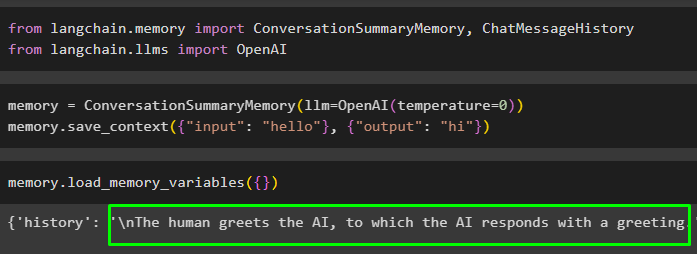
Pengguna juga bisa mendapatkan data dalam bentuk percakapan seperti setiap entitas dengan pesan terpisah:
Penyimpanan = Memori Ringkasan Percakapan ( llm = OpenAI ( suhu = 0 ) , pesan_kembali = BENAR )Penyimpanan. simpan_konteks ( { 'memasukkan' : 'Halo' } , { 'keluaran' : 'Hai apa kabar' } )
Untuk mendapatkan pesan AI dan manusia secara terpisah, jalankan metode load_memory_variables():
Penyimpanan. memuat_memori_variabel ( { } ) 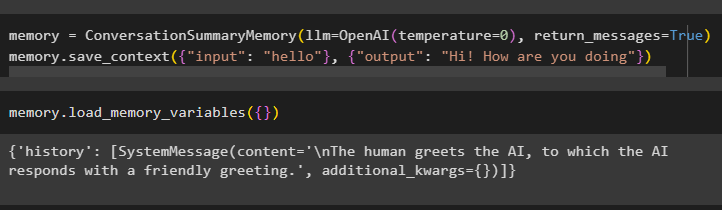
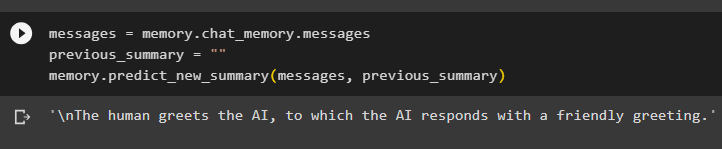
Simpan ringkasan percakapan di memori lalu jalankan memori untuk menampilkan ringkasan obrolan/percakapan di layar:
pesan = Penyimpanan. obrolan_memori . pesanringkasan_sebelumnya = ''
Penyimpanan. prediksi_ringkasan_baru ( pesan , ringkasan_sebelumnya )
Langkah 3: Menggunakan Ringkasan Percakapan Dengan Pesan yang Ada
Pengguna juga bisa mendapatkan ringkasan percakapan yang ada di luar kelas atau obrolan menggunakan pesan ChatMessageHistory(). Pesan-pesan ini dapat ditambahkan ke memori sehingga secara otomatis dapat menghasilkan ringkasan percakapan lengkap:
sejarah = Riwayat Pesan Obrolan ( )sejarah. tambahkan_pesan_pengguna ( 'Hai' )
sejarah. tambahkan_ai_message ( 'Hai, yang di sana!' )
Bangun model seperti LLM menggunakan metode OpenAI() untuk mengeksekusi pesan yang ada di obrolan_memori variabel:
Penyimpanan = Memori Ringkasan Percakapan. dari_pesan (llm = OpenAI ( suhu = 0 ) ,
obrolan_memori = sejarah ,
pesan_kembali = BENAR
)
Jalankan memori menggunakan buffer untuk mendapatkan ringkasan pesan yang ada:
Penyimpanan. penyangga 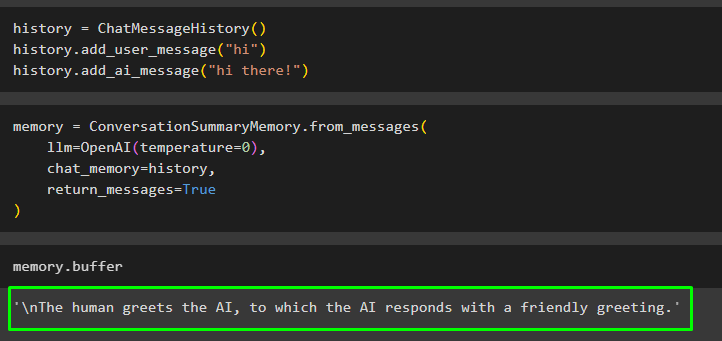
Jalankan kode berikut untuk membangun LLM dengan mengonfigurasi memori buffer menggunakan pesan obrolan:
Penyimpanan = Memori Ringkasan Percakapan (llm = OpenAI ( suhu = 0 ) ,
penyangga = '''Manusia menanyakan mesin yang bertanya tentang dirinya
Sistem menjawab bahwa AI dibuat untuk kebaikan karena dapat membantu manusia mencapai potensinya''' ,
obrolan_memori = sejarah ,
pesan_kembali = BENAR
)
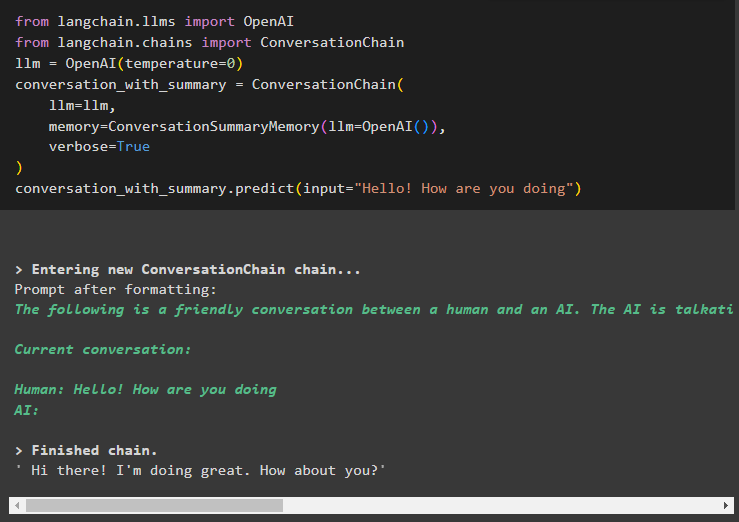
Langkah 4: Menggunakan Ringkasan Percakapan dalam Rantai
Langkah selanjutnya menjelaskan proses penggunaan ringkasan percakapan dalam rantai menggunakan LLM:
dari rantailang. llms impor OpenAIdari rantailang. rantai impor Rantai Percakapan
llm = OpenAI ( suhu = 0 )
percakapan_dengan_ringkasan = Rantai Percakapan (
llm = llm ,
Penyimpanan = Memori Ringkasan Percakapan ( llm = OpenAI ( ) ) ,
bertele-tele = BENAR
)
percakapan_dengan_ringkasan. meramalkan ( memasukkan = 'Halo apa kabar' )
Di sini kami mulai membangun rantai dengan memulai percakapan dengan pertanyaan yang sopan:
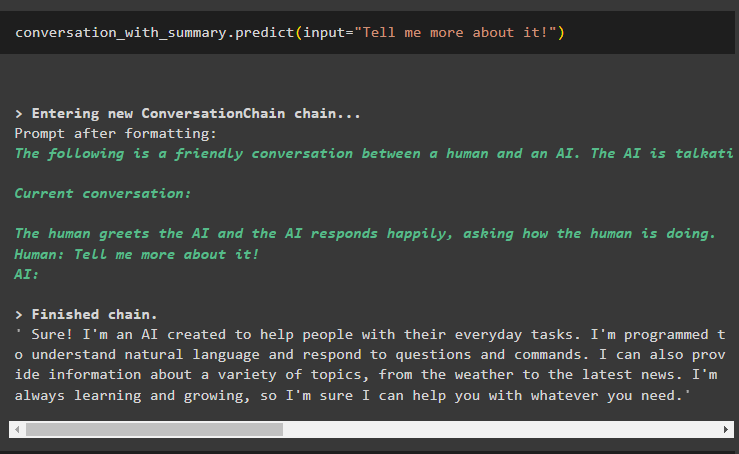
Sekarang masuklah ke dalam percakapan dengan menanyakan lebih banyak tentang keluaran terakhir untuk memperluasnya:
percakapan_dengan_ringkasan. meramalkan ( memasukkan = 'Ceritakan padaku lebih banyak tentang hal itu!' )Model tersebut telah menjelaskan pesan terakhir dengan pengenalan mendetail tentang teknologi AI atau chatbot:
Ekstrak poin menarik dari keluaran sebelumnya untuk mengarahkan percakapan ke arah tertentu:
percakapan_dengan_ringkasan. meramalkan ( memasukkan = 'Luar biasa. Seberapa bagus proyek ini?' )Di sini kami mendapatkan jawaban terperinci dari bot menggunakan perpustakaan memori ringkasan percakapan:
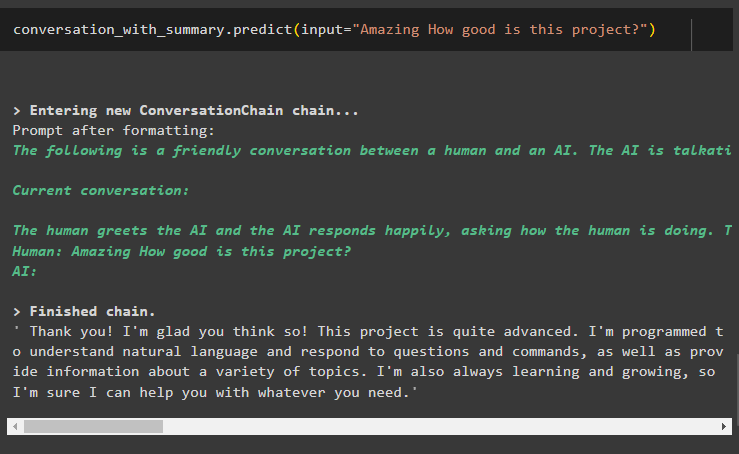
Sekian tentang penggunaan ringkasan percakapan di LangChain.
Kesimpulan
Untuk menggunakan pesan ringkasan percakapan di LangChain, cukup instal modul dan kerangka kerja yang diperlukan untuk menyiapkan lingkungan. Setelah lingkungan diatur, impor Memori Ringkasan Percakapan perpustakaan untuk membangun LLM menggunakan metode OpenAI(). Setelah itu, cukup gunakan ringkasan percakapan untuk mengekstrak keluaran detail dari model yang merupakan ringkasan percakapan sebelumnya. Panduan ini telah menguraikan proses penggunaan memori ringkasan percakapan menggunakan modul LangChain.