Panduan ini akan mengilustrasikan cara menggunakan VectorStoreRetrieverMemory menggunakan kerangka LangChain.
Bagaimana Cara Menggunakan VectorStoreRetrieverMemory di LangChain?
VectorStoreRetrieverMemory adalah perpustakaan LangChain yang dapat digunakan untuk mengekstrak informasi/data dari memori menggunakan penyimpanan vektor. Penyimpanan vektor dapat digunakan untuk menyimpan dan mengelola data untuk mengekstrak informasi secara efisien sesuai dengan perintah atau kueri.
Untuk mempelajari proses penggunaan VectorStoreRetrieverMemory di LangChain, cukup ikuti panduan berikut:
Langkah 1: Instal Modul
Mulai proses penggunaan memory retriever dengan menginstal LangChain menggunakan perintah pip:
pip instal langchain
Instal modul FAISS untuk mendapatkan data menggunakan pencarian kesamaan semantik:
pip instal faiss-gpu 
Instal modul chromedb untuk menggunakan database Chroma. Ia berfungsi sebagai penyimpanan vektor untuk membangun memori bagi retriever:
pip instal chromedb 
Modul tiktoken lain diperlukan untuk diinstal yang dapat digunakan untuk membuat token dengan mengubah data menjadi potongan yang lebih kecil:
pip instal tiktoken 
Instal modul OpenAI untuk menggunakan perpustakaannya untuk membangun LLM atau chatbots menggunakan lingkungannya:
pip instal openai 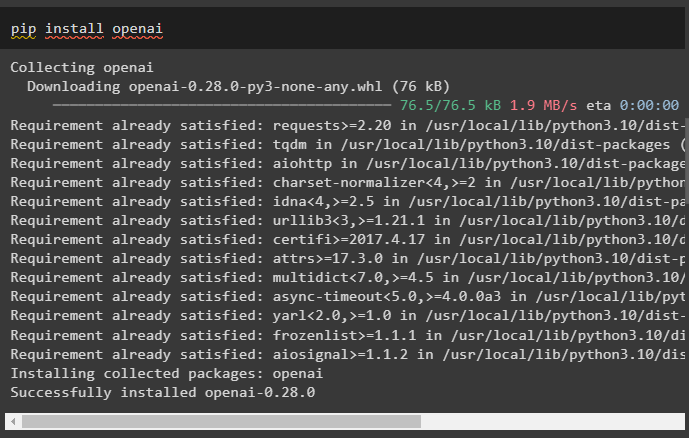
Siapkan lingkungan pada IDE Python atau notebook menggunakan kunci API dari akun OpenAI:
impor Andaimpor dapatkan pass
Anda . sekitar [ 'OPENAI_API_KEY' ] = dapatkan pass . dapatkan pass ( 'Kunci API OpenAI:' )
Langkah 2: Impor Perpustakaan
Langkah selanjutnya adalah mendapatkan perpustakaan dari modul ini untuk menggunakan memory retriever di LangChain:
dari rantailang. petunjuknya impor Templat Promptdari tanggal Waktu impor tanggal Waktu
dari rantailang. llms impor OpenAI
dari rantailang. penyematan . terbuka impor OpenAIEmbeddings
dari rantailang. rantai impor Rantai Percakapan
dari rantailang. Penyimpanan impor Memori VectorStoreRetriever
Langkah 3: Menginisialisasi Penyimpanan Vektor
Panduan ini menggunakan database Chroma setelah mengimpor perpustakaan FAISS untuk mengekstrak data menggunakan perintah input:
impor faissdari rantailang. toko dokumen impor Toko InMemoryDoc
#mengimpor perpustakaan untuk mengkonfigurasi database atau penyimpanan vektor
dari rantailang. toko vektor impor FAISS
#buat embeddings dan teks untuk menyimpannya di penyimpanan vektor
penyematan_ukuran = 1536
indeks = faiss. IndeksFlatL2 ( penyematan_ukuran )
penyematan_fn = OpenAIEmbeddings ( ) . sematkan_query
toko vektor = FAISS ( penyematan_fn , indeks , Toko InMemoryDoc ( { } ) , { } )
Langkah 4: Membangun Retriever yang Didukung oleh Toko Vektor
Bangun memori untuk menyimpan pesan terbaru dalam percakapan dan dapatkan konteks obrolan:
mengambil = toko vektor. sebagai_retriever ( pencarian_kwargs = dikte ( k = 1 ) )Penyimpanan = Memori VectorStoreRetriever ( mengambil = mengambil )
Penyimpanan. simpan_konteks ( { 'memasukkan' : 'Saya suka makan pizza' } , { 'keluaran' : 'fantastis' } )
Penyimpanan. simpan_konteks ( { 'memasukkan' : 'Aku pandai sepak bola' } , { 'keluaran' : 'Oke' } )
Penyimpanan. simpan_konteks ( { 'memasukkan' : 'Aku tidak suka politik' } , { 'keluaran' : 'Tentu' } )
Uji memori model menggunakan masukan yang diberikan oleh pengguna beserta riwayatnya:
mencetak ( Penyimpanan. memuat_memori_variabel ( { 'mengingatkan' : 'olahraga apa yang harus saya tonton?' } ) [ 'sejarah' ] ) 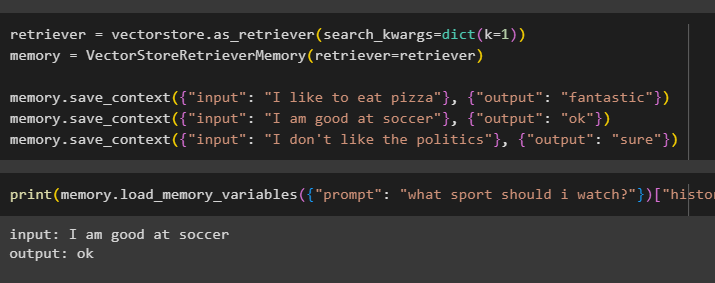
Langkah 5: Menggunakan Retriever dalam Rantai
Langkah selanjutnya adalah penggunaan memory retriever dengan rantai dengan membangun LLM menggunakan metode OpenAI() dan mengonfigurasi template prompt:
llm = OpenAI ( suhu = 0 )_DEFAULT_TEMPLATE = '''Ini adalah interaksi antara manusia dan mesin
Sistem menghasilkan informasi berguna dengan detail menggunakan konteks
Jika sistem tidak mempunyai jawaban untuk Anda, sistem hanya mengatakan saya tidak punya jawabannya
Informasi penting dari percakapan:
{sejarah}
(jika teksnya tidak relevan jangan gunakan)
Obrolan saat ini:
Manusia: {masukan}
AI:'''
MENGINGATKAN = Templat Prompt (
masukan_variabel = [ 'sejarah' , 'memasukkan' ] , templat = _DEFAULT_TEMPLATE
)
#konfigurasi ConversationChain() menggunakan nilai parameternya
percakapan_dengan_ringkasan = Rantai Percakapan (
llm = llm ,
mengingatkan = MENGINGATKAN ,
Penyimpanan = Penyimpanan ,
bertele-tele = BENAR
)
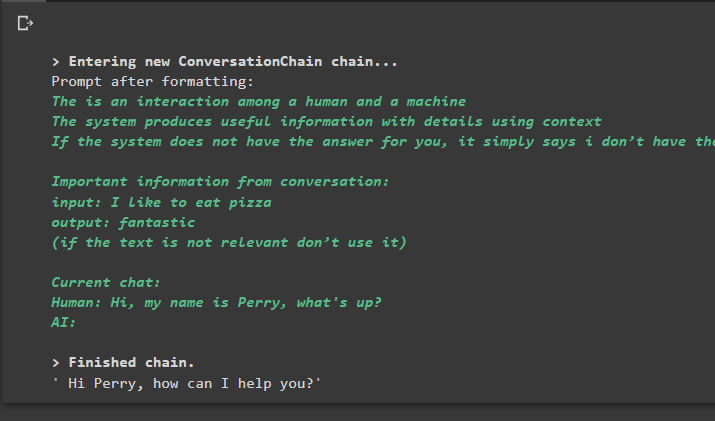
percakapan_dengan_ringkasan. meramalkan ( memasukkan = 'Hai, namaku Perry, ada apa?' )
Keluaran
Menjalankan perintah akan menjalankan rantai dan menampilkan jawaban yang diberikan oleh model atau LLM:
Lanjutkan percakapan menggunakan prompt berdasarkan data yang disimpan di penyimpanan vektor:
percakapan_dengan_ringkasan. meramalkan ( memasukkan = 'apa olahraga favoritku?' ) 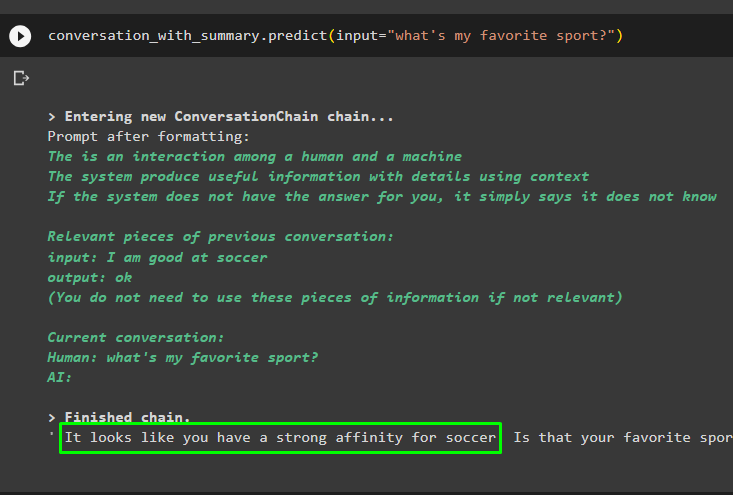
Pesan sebelumnya disimpan dalam memori model yang dapat digunakan oleh model untuk memahami konteks pesan:
percakapan_dengan_ringkasan. meramalkan ( memasukkan = 'Apa makanan kesukaanku' ) 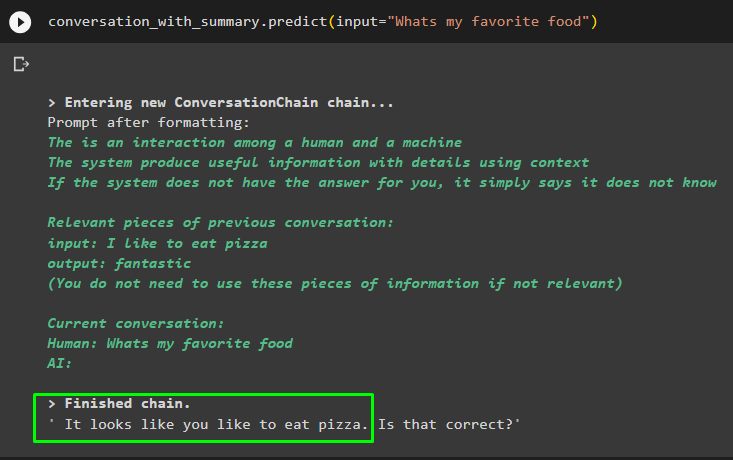
Dapatkan jawaban yang diberikan kepada model di salah satu pesan sebelumnya untuk memeriksa cara kerja memory retriever dengan model obrolan:
percakapan_dengan_ringkasan. meramalkan ( memasukkan = 'Apa nama saya?' )Model telah menampilkan keluaran dengan benar menggunakan pencarian kesamaan dari data yang disimpan di memori:
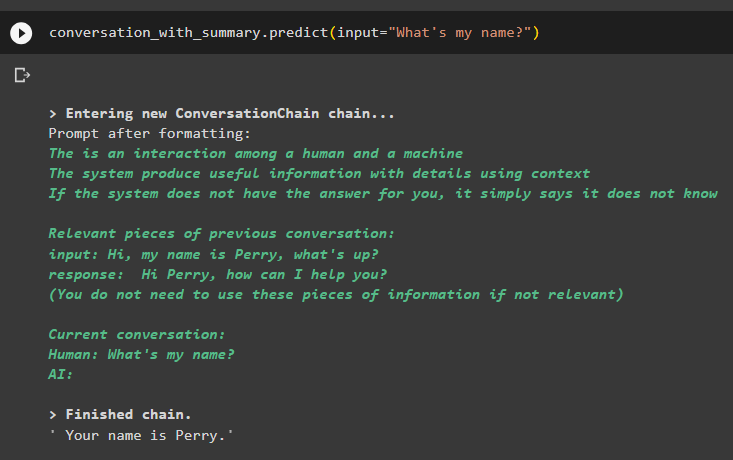
Sekian tentang penggunaan vector store retriever di LangChain.
Kesimpulan
Untuk menggunakan memory retriever berdasarkan penyimpanan vektor di LangChain, cukup instal modul dan kerangka kerja dan atur lingkungannya. Setelah itu, impor perpustakaan dari modul untuk membangun database menggunakan Chroma dan kemudian atur template prompt. Uji retriever setelah menyimpan data di memori dengan memulai percakapan dan mengajukan pertanyaan terkait pesan sebelumnya. Panduan ini telah menguraikan proses penggunaan perpustakaan VectorStoreRetrieverMemory di LangChain.