Di blog ini, kami akan fokus pada cara meningkatkan pemanfaatan GPU di PyTorch.
Bagaimana Cara Meningkatkan Pemanfaatan GPU di PyTorch?
Ada beberapa teknik yang dapat digunakan untuk meningkatkan pemanfaatan GPU dan memastikan sumber daya perangkat keras terbaik digunakan untuk memproses model pembelajaran mesin yang kompleks. Taktik ini melibatkan pengeditan kode dan pemanfaatan fitur PyTorch. Beberapa tip dan trik penting tercantum di bawah ini:
- Memuat Data dan Ukuran Batch
- Model yang Kurang Bergantung pada Memori
- Petir PyTorch
- Sesuaikan Pengaturan Runtime di Google Colab
- Hapus Cache untuk Optimasi
Memuat Data dan Ukuran Batch
“ Pemuat data ” di PyTorch digunakan untuk menentukan spesifikasi data yang akan dimuat ke dalam prosesor dengan setiap forward pass model pembelajaran mendalam. Lebih besar “ ukuran tumpukan ” data akan membutuhkan lebih banyak daya pemrosesan dan akan meningkatkan pemanfaatan GPU yang tersedia.
Sintaks untuk menetapkan Dataloader dengan ukuran batch tertentu di PyTorch ke variabel khusus diberikan di bawah ini:
Peningkatan_GPU_Utilisasi = DataLoader ( ukuran_batch = 32 )
Model yang Kurang Bergantung pada Memori
Setiap arsitektur model memerlukan volume “ Penyimpanan ” untuk bekerja pada tingkat optimal. Model yang efisien dalam menggunakan lebih sedikit memori per unit waktu mampu bekerja dengan ukuran batch yang jauh lebih besar dibandingkan model lainnya.
Petir PyTorch
PyTorch memiliki versi yang diperkecil yaitu “ Petir PyTorch ”. Ini dioptimalkan untuk kinerja secepat kilat seperti yang terlihat dari namanya. Lightning menggunakan GPU secara default dan menawarkan pemrosesan yang jauh lebih cepat untuk model pembelajaran mesin. Keuntungan utama Lightning adalah kurangnya persyaratan kode boilerplate yang dapat menghambat pemrosesan.
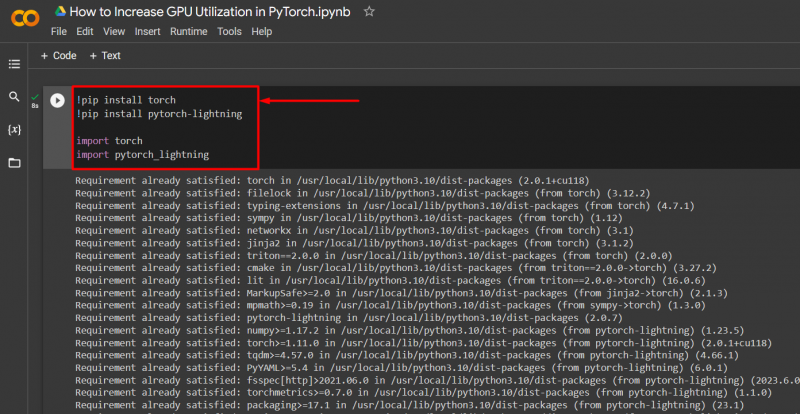
Impor perpustakaan yang diperlukan ke dalam proyek PyTorch dengan sintaks yang diberikan di bawah ini:
! pip instal obor
! pip instal pytorch - petir
impor obor
impor pytorch_lightning
Sesuaikan Pengaturan Runtime di Google Colab
Google Colaboratory adalah IDE cloud yang menyediakan akses GPU gratis kepada penggunanya untuk pengembangan model PyTorch. Secara default, proyek Colab berjalan pada CPU tetapi pengaturannya dapat diubah.
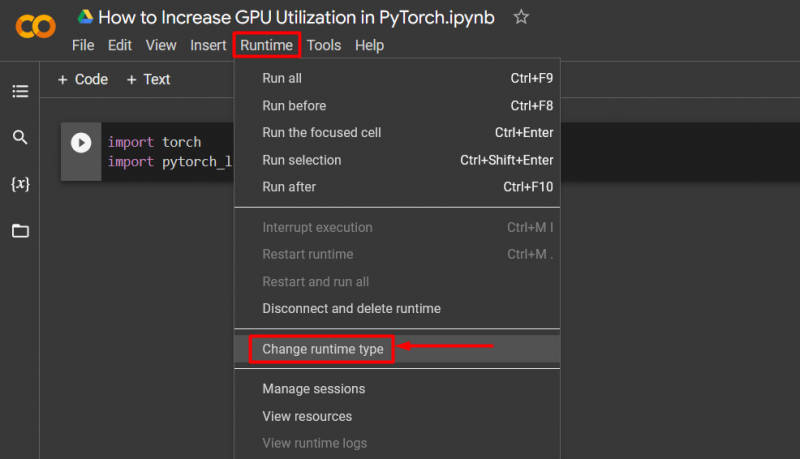
Buka buku catatan Colab, buka “ Waktu proses ” di bilah menu, dan gulir ke bawah ke “ Ubah pengaturan waktu proses ”:
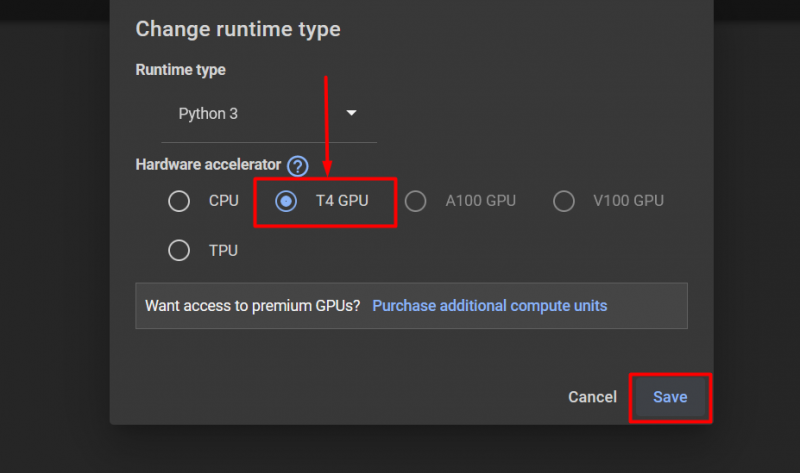
Kemudian, pilih “GPU T4” pilihan dan klik “ Menyimpan ” untuk menerapkan perubahan guna memanfaatkan GPU:
Hapus Cache untuk Optimasi
PyTorch memungkinkan penggunanya untuk menghapus cache memori agar dapat mengosongkan ruang untuk menjalankan proses baru. “ Cache ” menyimpan data dan informasi tentang model yang dijalankan sehingga dapat menghemat waktu yang akan digunakan dalam memuat ulang model tersebut. Menghapus cache memberi pengguna lebih banyak ruang untuk menjalankan model baru.
Perintah untuk menghapus cache GPU diberikan di bawah ini:
obor. berbeda . kosong_cache ( ) 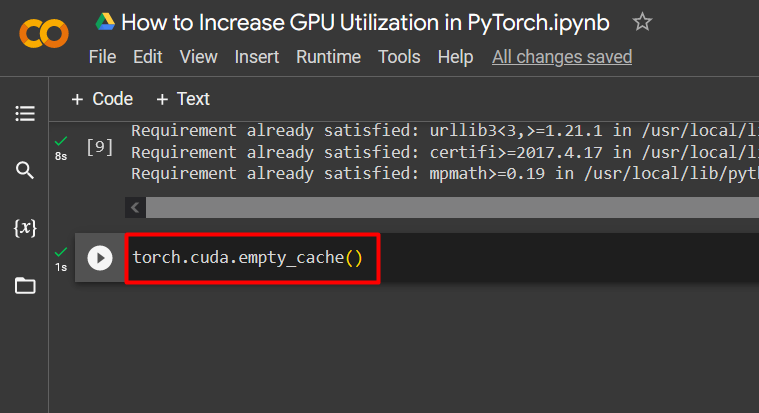
Tips ini digunakan untuk mengoptimalkan jalannya model pembelajaran mesin dengan GPU di PyTorch.
Tip Pro
Google Colab memungkinkan penggunanya mengakses detail tentang penggunaan GPU dengan “ nvidia ” untuk mendapatkan informasi tentang di mana sumber daya perangkat keras digunakan. Perintah untuk menampilkan detail pemanfaatan GPU diberikan di bawah ini:
! nvidia - smi 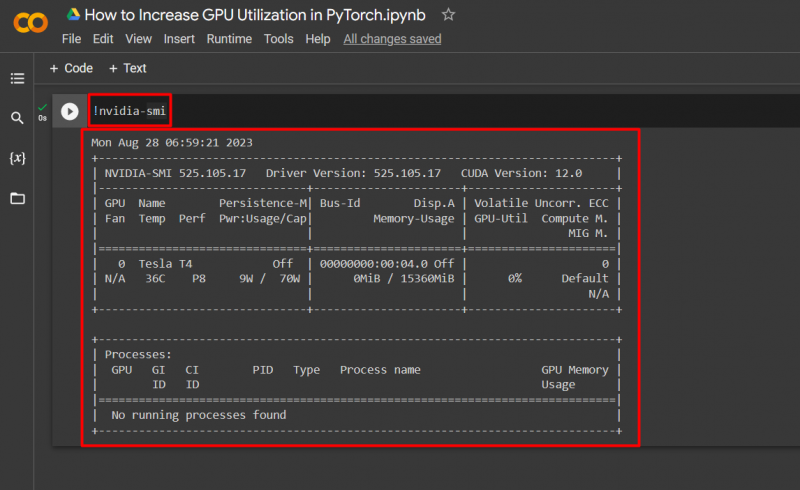
Kesuksesan! Kami baru saja mendemonstrasikan beberapa cara untuk meningkatkan pemanfaatan GPU di PyTorch.
Kesimpulan
Tingkatkan pemanfaatan GPU di PyTorch dengan menghapus cache, menggunakan PyTorch Lightning, menyesuaikan pengaturan runtime, menggunakan model yang efisien, dan ukuran batch yang optimal. Teknik-teknik ini sangat membantu dalam memastikan bahwa model pembelajaran mendalam memiliki kinerja terbaik dan mampu menarik kesimpulan dan kesimpulan yang valid dari data yang tersedia. Kami telah mendemonstrasikan teknik untuk meningkatkan pemanfaatan GPU.