Skalabilitas
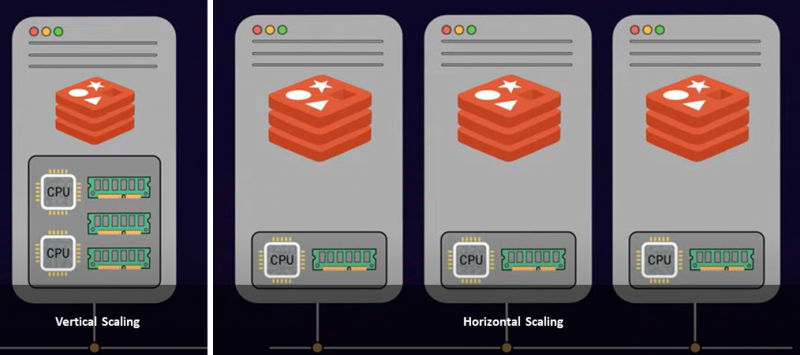
Ada dua pendekatan umum untuk menskalakan server: penskalaan vertikal dan penskalaan horizontal. Penskalaan vertikal atau penskalaan adalah tempat Anda menambahkan lebih banyak daya dan sumber daya ke server Anda, seperti lebih banyak CPU, memori, dan penyimpanan, yang mahal. Di sisi lain, penskalaan horizontal menambahkan banyak node ke kumpulan sumber daya Anda yang ada. Ini disebut penskalaan. Jadi, berdasarkan batasan dan persyaratan Anda, terserah Anda untuk memiliki satu instans server yang lebih besar atau menggunakan beberapa node server.
Asumsikan Anda memiliki 100 GB RAM dan perlu menyimpan 200 GB data. Dalam hal ini, Anda memiliki dua pilihan:
- Tingkatkan dengan menambahkan lebih banyak RAM ke sistem
- Skalakan dengan menambahkan instance server lain dengan RAM 100 GB
Jika Anda telah mencapai batas RAM maksimum dalam infrastruktur Anda, maka penskalaan adalah pendekatan yang ideal. Selain itu, penskalaan akan meningkatkan throughput database dengan margin yang sangat besar.
Redis Sharding
Ini adalah fakta yang diketahui bahwa Redis beroperasi pada satu utas. Jadi, Redis tidak dapat menggunakan banyak core CPU server Anda untuk memproses perintah. Oleh karena itu, menambahkan lebih banyak core CPU tidak memberi Anda banyak throughput atau performa dengan Redis. Tidak demikian halnya dengan membagi data Anda di antara beberapa contoh server. Menambahkan beberapa server dan mendistribusikan kumpulan data di antaranya memungkinkan pemrosesan permintaan klien secara paralel, yang meningkatkan throughput. Selain itu, kinerja keseluruhan dapat meningkat mendekati linier.
Pendekatan pemisahan atau pendistribusian data di antara beberapa server dengan pertimbangan penskalaan ini disebut pecahan . Semua server yang menyimpan sebagian data dipanggil pecahan .
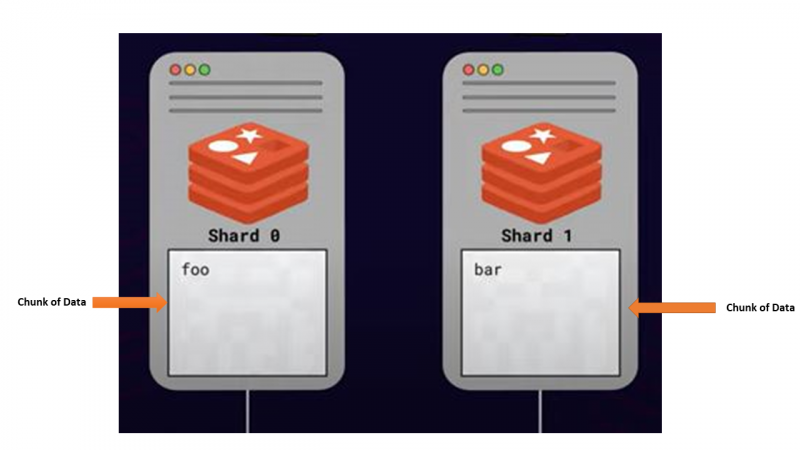
Bagaimana Sharding Dilakukan — Algorithmic Sharding
Salah satu perhatian utama dengan sharding adalah bagaimana menemukan kunci yang diberikan di antara beberapa node Redis. Karena kunci yang diberikan dapat disimpan di shard yang tersedia, meminta semua shard untuk menemukan kunci tertentu bukanlah pilihan terbaik. Jadi, harus ada cara untuk memetakan setiap kunci ke shard tertentu, dan Redis menggunakan strategi sharding algoritmik.
Pendekatan yang paling umum adalah menghitung nilai hash menggunakan nama kunci Redis dan modulo. Kemudian, bagi dengan pecahan Redis yang tersedia di sistem.
HASH_SLOT = mod CRC16(kunci). 16384Ini adalah solusi yang cukup bagus selama jumlah total pecahannya konstan. Setiap kali Anda menambahkan instans server Reids baru, nilai yang dihasilkan untuk kunci tertentu dapat berubah karena jumlah total pecahan telah meningkat. Itu akan berakhir dengan menanyakan pecahan Redis yang salah. Karenanya, Anda harus mengikuti proses resharding dengan menghitung shard baru untuk setiap kunci dan mentransfer data ke server yang benar, yang rumit dan bukan tugas sepele jika jumlah total shard Anda meningkat dari waktu ke waktu.
Redis menggunakan entitas logis baru yang disebut a slot hash untuk mencegah masalah ini. Beberapa slot hash tersedia untuk shard tertentu, dan satu slot hash dapat menampung beberapa kunci Redis. Ada 16384 slot hash di kluster database Redis yang tetap tidak berubah. Pembagian modulo dilakukan dengan jumlah slot hash alih-alih jumlah pecahan. Ini memberikan posisi yang benar dari slot hash untuk kunci yang ditentukan bahkan ketika jumlah pecahan meningkat. Ini menyederhanakan proses resharding dengan memindahkan slot hash dari satu shard ke shard baru yang membagi data di berbagai instance Redis sesuai kebutuhan.
Manfaat Redis Sharding
Redis sharding memungkinkan beberapa manfaat untuk sistem database Anda dengan sedikit perubahan.
Hasil Tinggi
Karena Redis adalah single-threaded, pemrosesan beberapa permintaan klien tidak dapat diproses secara paralel menggunakan beberapa inti CPU. Jadi, menambahkan shard atau instans server baru akan menjamin bahwa Anda dapat melakukan operasi Redis secara paralel. Ini meningkatkan operasi per detik dalam database Redis Anda, yang pada akhirnya memberi Anda hasil yang tinggi.
Ketersediaan Tinggi
Dengan pendekatan sharding, klaster Redis dapat menyiapkan arsitektur master-replika yang memastikan ketersediaan dan ketahanan yang tinggi.
Baca Replika
Sharding memungkinkan Anda menyimpan salinan persis data Anda dan menyediakan operasi baca melalui instans Redis terpisah, yang meningkatkan kinerja eksekusi kueri baca Anda.
Terlepas dari manfaat ini, sharding dapat menyebabkan situasi otak terbelah saat Anda memiliki shard dalam jumlah genap di kluster Redis. Jadi, disarankan untuk menyimpan shard dalam jumlah ganjil di klaster Redis Anda.
Kesimpulan
Ringkasnya, Redis sharding membagi data di antara beberapa server, yang memungkinkan penskalaan dan throughput tinggi untuk database Anda. Seperti yang telah dibahas, Redis menggunakan strategi sharding algoritmik untuk mengarahkan permintaan klien ke shard yang tepat. Ini memiliki beberapa kelemahan ketika jumlah pecahan meningkat. Jadi, alih-alih jumlah total pecahan, Redis menggunakan jumlah slot hash untuk menghitung pecahan yang sesuai. Dengan diperkenalkannya sharding, database Redis menyediakan ketersediaan tinggi, throughput tinggi, dan kinerja tinggi.